Samenvatting
Spekulative Dekodierung ermöglicht es LLMs, Texte dreimal schneller zu generieren und verändert die Zukunft von KI und Suchtechnologie.
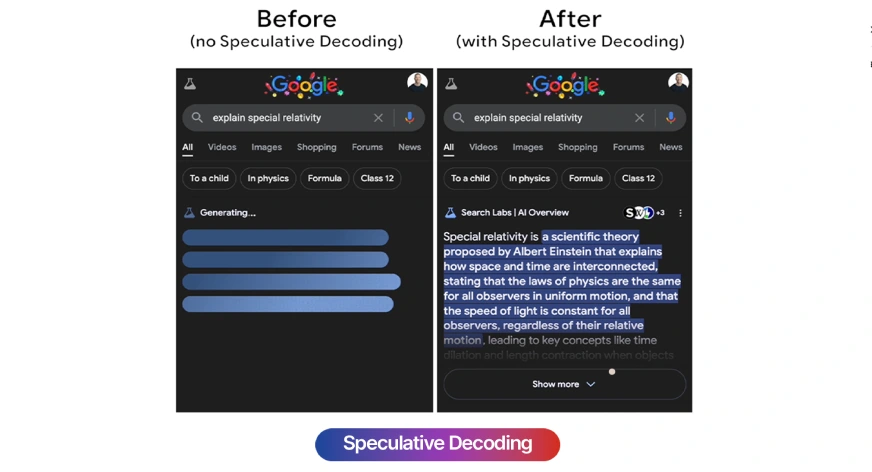
Schnellere Texterzeugung durch spekulative Dekodierung
Neueste Forschungen zeigen, dass Language Models (LLMs) durch spekulative Dekodierung ihre Reaktionszeiten erheblich verbessern können. Diese Technologie ermöglicht es Modellen, proaktiv Texte zu generieren, wodurch die Geschwindigkeit um bis zu 300% im Vergleich zu herkömmlichen Generierungsmethoden steigt.
Auswirkungen auf den BI- und KI-Markt
Diese Entwicklung hat große Auswirkungen auf den Business-Intelligence-Markt, in dem Geschwindigkeit und Effizienz von entscheidender Bedeutung sind. Konkurrenten können die Vorteile von schnelleren Analysen nutzen, was zu einem Wandel in der Verarbeitung und Präsentation von Daten führt. In einer Zeit, in der Datenanalyse immer drängender wird, passt dieser Trend zum explosiven Wachstum von KI-Anwendungen in Geschäftsprozessen.
Handlungsbedarf für BI-Profis
BI-Profis sollten die Implementierung und Potenziale der spekulativen Dekodierung beobachten, da diese Technologie die Art und Weise, wie Daten erfasst und interpretiert werden, revolutionieren könnte. Es ist entscheidend, sich auf den Wandel zu schnelleren und relevanteren Erkenntnissen vorzubereiten.
Deepen your knowledge
Knowledge Base
AI in Power BI — Copilot, Smart Narratives and more
Discover all AI features in Power BI: from Copilot and Smart Narratives to anomaly detection and Q&A. Complete overview ...
Knowledge BaseChatGPT and BI — How AI is transforming data analysis
Discover how ChatGPT and generative AI are changing business intelligence. From generating SQL and DAX to automating dat...
Knowledge BasePredictive Analytics — What can it do for your business?
Discover what predictive analytics is, how it works, and how to apply it in your business. From the 4 levels of analytic...