Samenvatting
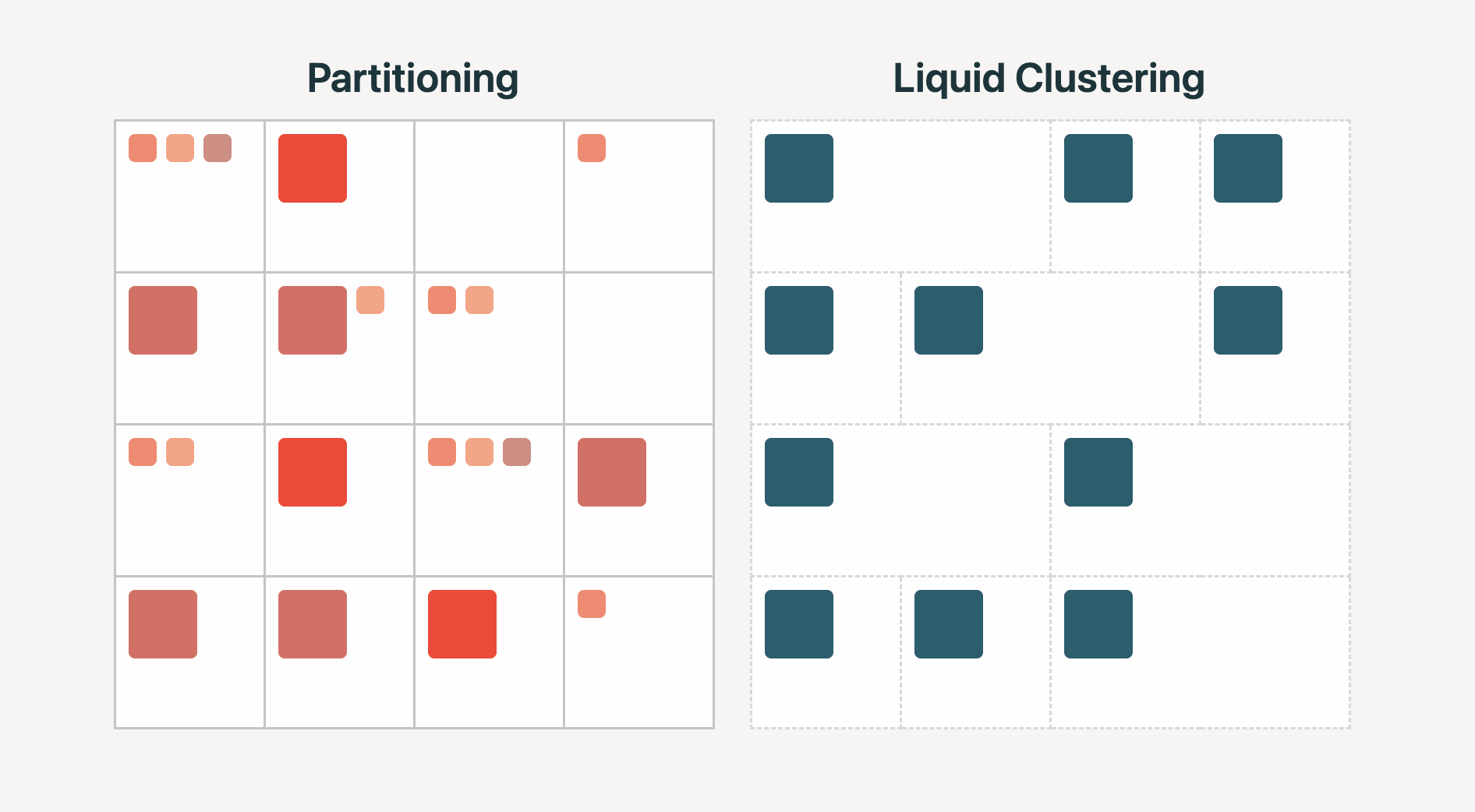
Liquid Clustering biedt betere prestaties dan partitionering
Liquid Clustering is een geavanceerde data-indeling die de beperkingen van traditionele partitionering omzeilt en betere prestaties levert.
Waarom Liquid Clustering nu toonaangevend is
Liquid Clustering biedt aanzienlijke verbeteringen in query latency, write throughput en opslag efficiëntie vergeleken met traditionele partitioneringsmethoden. De technologie maakt gebruik van clustering keys voor een optimale organisatie van bestanden zonder de beperkingen van hoge cardinaliteit of de noodzaak voor frequente herindelingen. Dit maakt het ideaal voor het dynamische karakter van moderne Lakehouses waarin real-time gegevensstromen en veranderende querypatronen voorkomen.
De impact op de BI-sector
Deze ontwikkeling versterkt de flexibiliteit en schaalbaarheid van gegevensbeheeroplossingen binnen de Lakehouse-architectuur. Het laat zien dat de beperkingen van traditionele methoden, zoals over-partitionering en problemen met kleine bestanden, kunnen worden overwonnen. Voor BI-professionals betekent dit een verschuiving naar een efficiëntere aanpak van data-indelingen, met minder tijd besteed aan herstructurering en meer focus op analyse en inzichten.
Overweging voor BI-professionals
BI-professionals zouden moeten overwegen om Liquid Clustering te implementeren voor hun datasets om de efficiëntie en prestaties van hun gegevensinfrastructuur te verbeteren. Dit zal niet alleen de beheerkosten verlagen, maar ook de algehele responsiviteit van data-analyseprocessen vergroten.
Verdiep je kennis
Kennisbank
Data lakehouse uitgelegd — Het beste van twee werelden
Wat is een data lakehouse en waarom combineert het het beste van data warehouses en data lakes? Vergelijking, architectu...
KennisbankETL uitgelegd — Extract, Transform, Load in gewone taal
Wat is ETL? Leer hoe Extract, Transform en Load werkt, het verschil met ELT, en welke tools je kunt gebruiken. Helder ui...
Gerelateerde artikelen

Frontier Data Agents: beter in kwaliteit en kosten dan coding agents
Frontier Data Agents overtreffen algemene coding agents in nauwkeurigheid en kostenbesparing.

10 Mythen over Data Warehouse Migratie die AI-klaarheid Belemmeren (en Jouw Plan voor Soepele Modernisering)
Een succesvolle migratie naar een modern data warehouse is essentieel voor de AI-klaarheid van ondernemingen.

Waarom agentische analytics begint met een goed datalaag
Met een goed beheerde datalaag kan agentische analytics organisaties in staat stellen om sneller en effectiever beslissi...

Data-native AI-agents: integratie met jouw data noodzakelijk
Data-native AI-agents moeten dicht bij jouw data draaien.