Samenvatting
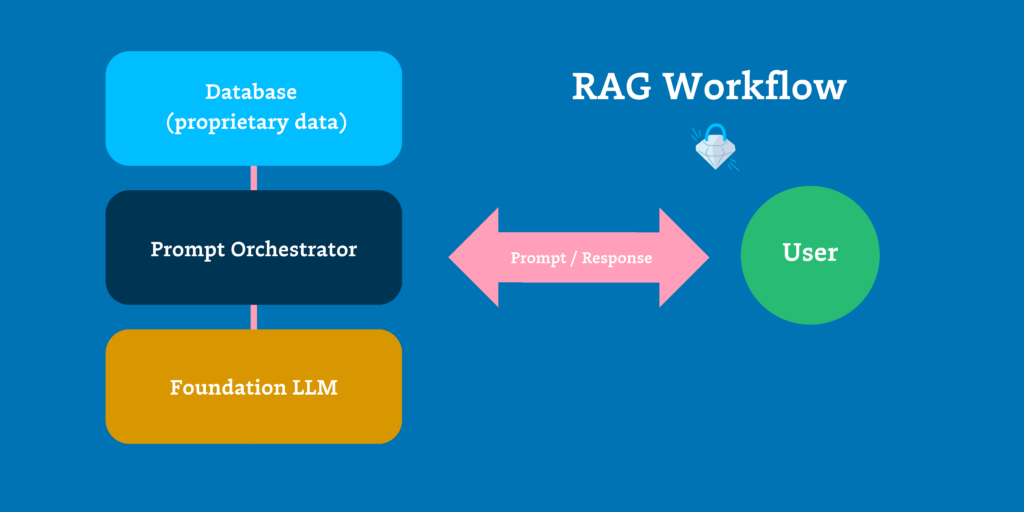
Om succesvol gebruik te maken van Large Language Models (LLMs) op enterprise-niveau, is het cruciaal om de data pipelines met de nodige zorg te beheren. De combinatie van Retrieval-Augmented Generation (RAG) en fine tuning vormt de sleutel voor het creëren van een competitief voordeel in de snel veranderende AI-landschap.
Verdiep je kennis
Kennisbank
ETL uitgelegd — Extract, Transform, Load in gewone taal
Wat is ETL? Leer hoe Extract, Transform en Load werkt, het verschil met ELT, en welke tools je kunt gebruiken. Helder ui...
KennisbankData lakehouse uitgelegd — Het beste van twee werelden
Wat is een data lakehouse en waarom combineert het het beste van data warehouses en data lakes? Vergelijking, architectu...
KennisbankData-driven werken — Hoe begin je als organisatie?
Leer hoe je als organisatie data-driven gaat werken. Van data-volwassenheid tot cultuurverandering: een praktisch stappe...
Gerelateerde artikelen

5 Lagen van Data Lakehouse Architectuur Uitleggen
Dit artikel legt de vijf lagen van data lakehouse architectuur uit, waaronder Ingestion, Storage, Metadata, API en Consu...

Data Observability: Betrouwbaarheid in het AI Tijdperk
Data observability wordt cruciaal in het AI-tijdperk, met een sterke focus op het verbeteren van probleemoplossing, de e...

Monte Carlo Brengt Data Observability naar Microsoft Azure Synapse en Microsoft Fabric
Monte Carlo introduceert data observability voor Microsoft Azure Synapse en Microsoft Fabric. Deze functionaliteit maakt...

5 Harde Waarheden Over Generatieve AI voor Technologieleiders
Het implementeren van generatieve AI die daadwerkelijk bedrijfswaarde oplevert, is een uitdagende taak. Technologieleide...