Summary
Speculative decoding enables LLMs to generate text three times faster, reshaping the future of AI and search technology.
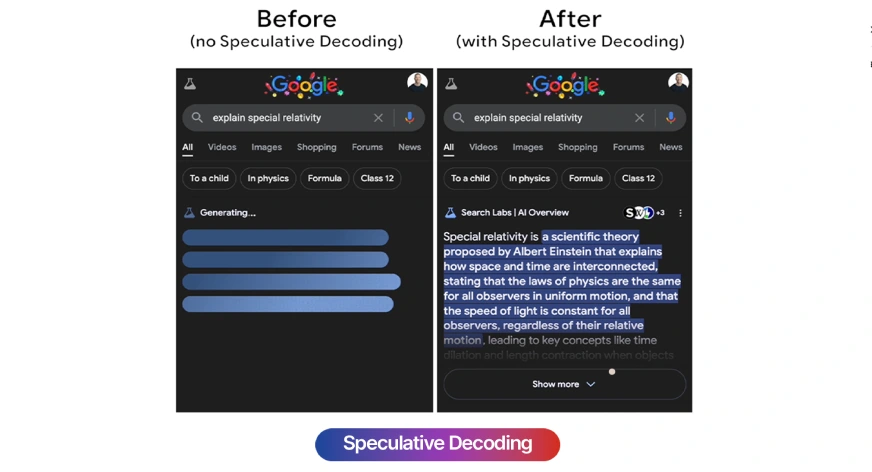
Faster Text Generation through Speculative Decoding
Recent research reveals that Language Models (LLMs) can significantly enhance their response times using speculative decoding. This technology allows models to generate text proactively, increasing speed by up to 300% compared to traditional generation methods.
Implications for the BI and AI Market
This development carries major implications for the business intelligence market, where speed and efficiency are critical. Competitors can leverage the advantages of faster analyses, leading to a shift in how data is processed and presented. In an era where data analysis is becoming increasingly urgent, this trend aligns with the explosive growth of AI applications in business processes.
Takeaway for BI Professionals
BI professionals should keep an eye on the implementation and potential of speculative decoding, as this technology could revolutionize how data is recorded and interpreted. Being prepared for the shift towards faster and more relevant insights is essential.
Deepen your knowledge
Knowledge Base
AI in Power BI — Copilot, Smart Narratives and more
Discover all AI features in Power BI: from Copilot and Smart Narratives to anomaly detection and Q&A. Complete overview ...
Knowledge BaseChatGPT and BI — How AI is transforming data analysis
Discover how ChatGPT and generative AI are changing business intelligence. From generating SQL and DAX to automating dat...
Knowledge BasePredictive Analytics — What can it do for your business?
Discover what predictive analytics is, how it works, and how to apply it in your business. From the 4 levels of analytic...